With the advent of cloud and container technologies, businesses and organizations are adopting them at an exponential rate. Technologies like Cloudtrail, Azure, and Kubernetes, all produce logs in the form of JSON data that are deeply nested, meaning that it contains a lot of nested objects and arrays. This nesting can make it difficult to evaluate and use the log data for generating analytics.
With this in mind, JSON Parser, a new application plugin from Logpoint, allows for full support of JSON data types in search queries. This plugin parses JSON log data and makes it available as individual fields, enabling users to search, filter, and analyze JSON logs. This capability improves the efficiency and effectiveness of log management and security analytics, especially for users who work with logs from multiple sources that may contain JSON data.


What Capabilities Does JSON Parser Add to Logpoint?
-
Easier to handle complex JSON log events and supports JSON data types, enhancing the capabilities of Logpoint search queries.
-
Enables search queries to be performed at a more granular level and improves the possibilities for aggregating on event sub-levels of JSON logs.
-
Enables direct extraction of values from JSON data in search queries, reducing the need for exhaustive parsing and resulting in cleaner parsing with fewer indexed fields and less storage space usage.
Ingest, parse, and extract JSON logs in one platform
Major services, for instance, CloudTrail, an AWS service that logs events in JSON format, within an AWS account. These logs contain details about AWS API calls such as the user who made the call, the timestamp, and affected resources. The logs can also include nested objects representing request parameters, response data, and authentication information. Additionally, each of these objects could also contain arrays of values, further increasing the depth of the nesting.
As such, the JSON Parser plugin helps to solve this problem by providing a way to parse and extract information from JSON logs in real time as they are ingested into Logpoint. In the following indexed log, the "instanceId" is extracted from either the "responseelements_instancesset_items" or "instance_item" JSON array objects and renamed as "instance_id" in the resulting indexed log.
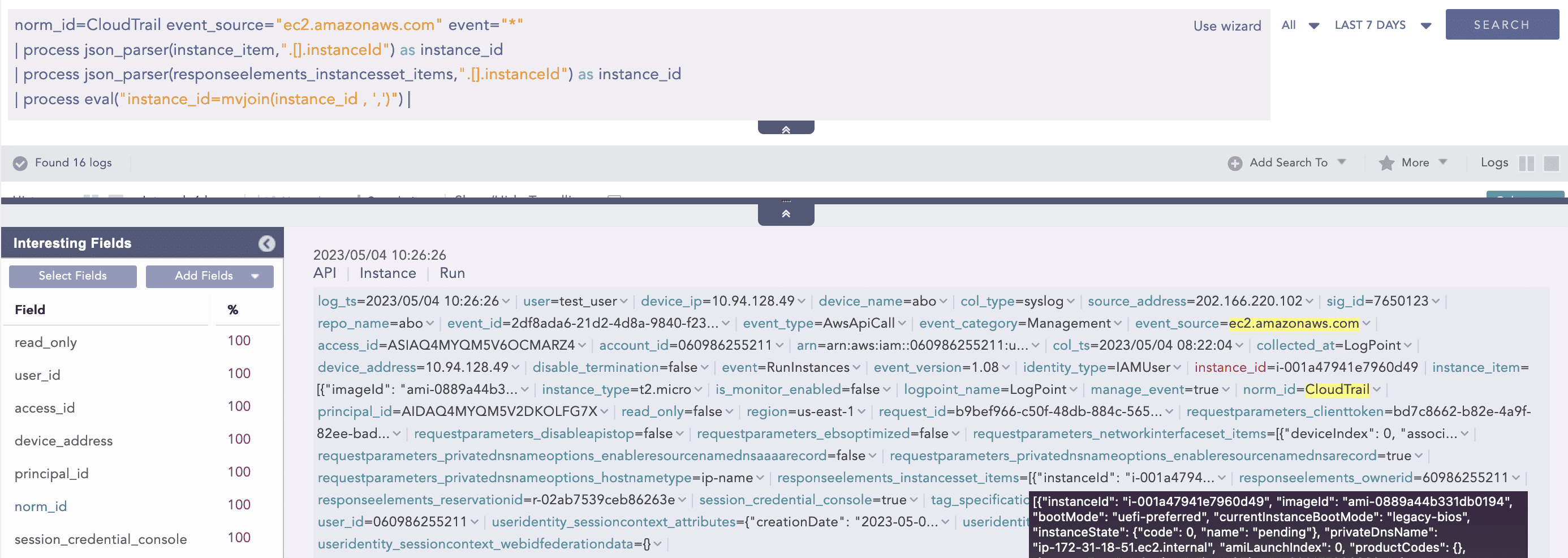
Extraction of values from JSON objects
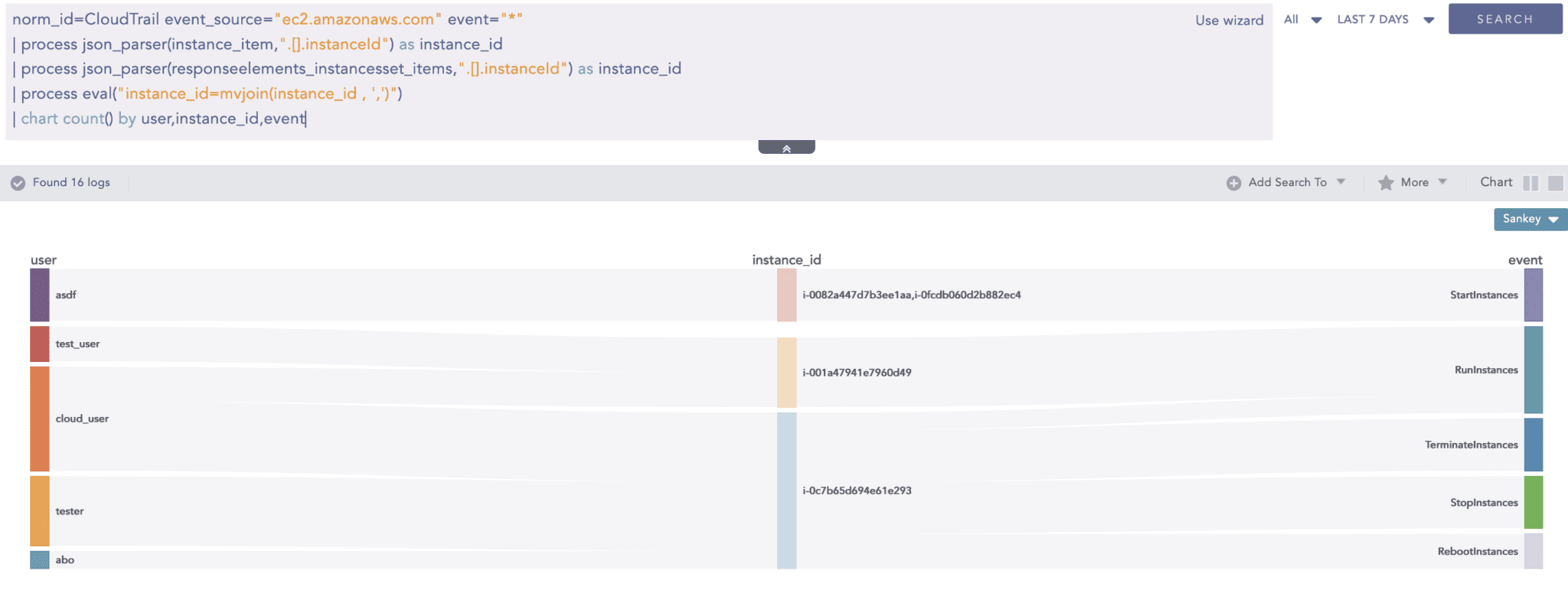
Event performed on EC2 instance by a user
JSON Parser Process commands
The JSON Parser application in Logpoint Converged SIEM contains three process commands, each of which serves a specific purpose in parsing JSON log data.
-
JSONParser
-
JQParser
-
JSONExpand
Command: JSONParser
This process command is used to parse JSON log data and make it available as individual fields that can be used in search queries. The JSONParser command can be used to extract specific fields from nested JSON data, making it easier to search, filter, and analyze JSON logs.
Currently supported filters are:
1. Access Objects
Access data in a JSON object using the dot operator.
The value from the above JSON can be extracted with the following Logpoint query.
Result:
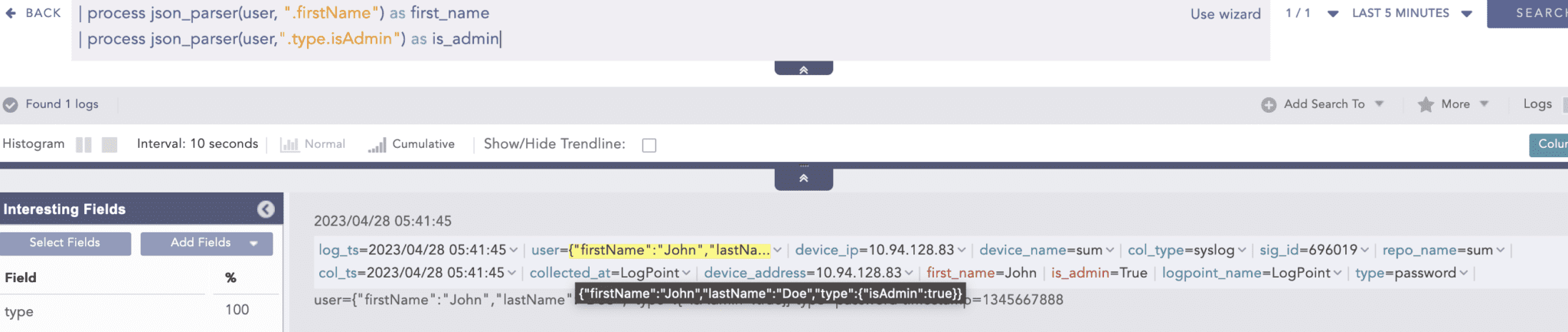
Object access using JSONParser
2. Access arrays/lists
Access JSON array using array indexing.
All items from the list of JSON objects can be extracted with the following Logpoint query.
Result:

Array access using JSONParser
Command: JQParser
This process command uses the JQ tool, a lightweight and flexible command-line JSON processor, to parse JSON log data. JQParser allows for advanced querying and manipulation of JSON data, making it particularly useful for complex JSON log structures.
Important: To perform simple data extraction operations such as accessing objects and arrays, it is recommended to use JSONParser as JQParser supports a wide range of JQ filters that adversely affects its performance.
Example:
Following is the usage of the evaluation filter of JQ filters.
Result:

Evaluation of JSON data
Here are the filters that the JQParser process command support: jq Manual (development version)
Documentation link: Logpoint Documentation: JQParser
Command: JSONExpand
When a JSON array is present in a log event, the JSONExpand command creates multiple instances of the log based on the number of items present in the array. Each list item of the array is then converted into an individual indexed log with other values of the original log intact.
Before:

After execution of the JSONExpand command on the above single log.
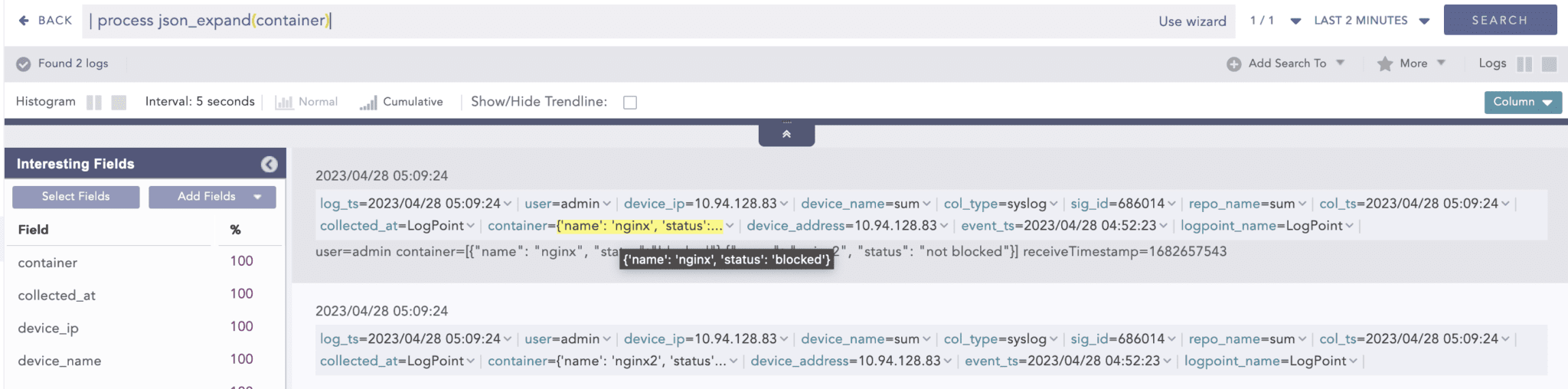
JSONExpand creates multiple instances from a single log
Additional Use Cases
Aggregation on sub-events inside a log
Generally, aggregation, such as chart aggregation, is performed on multiple log events. There was no way to use aggregation if a single log event contains multiple sub-events that need aggregations.
Consider the following portion of the Cloudtrails log:
In this log event, “Statement“ inside “bucketPolicy“ contain multiple statement events as a list. JSONExpand can split a single log into multiple instances concerning the number of list items. In the above example, there are 3 Statement events, so the above log would be split into 3 logs and after that, they can be used in chart aggregation.
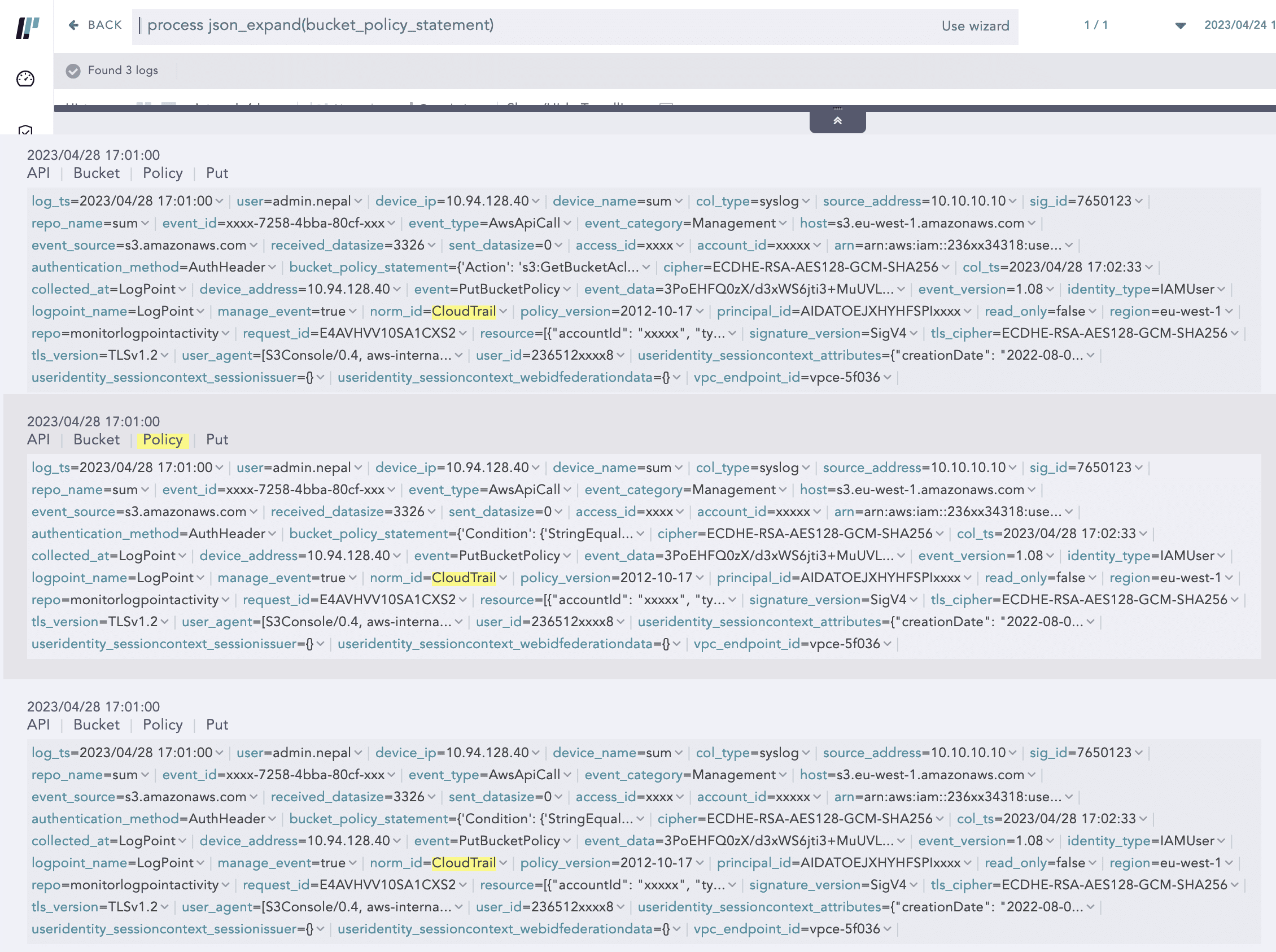
Three log instances from a single log
As JSONExpand created the 3 instances from one log, now aggregation commands like chart and time chart can be applied for sub-events of an original log event.

Action performed on a bucket by a user and its corresponding effect
Eliminate Unnecessary Indexing of Fields from Compiled Normalizers
Compiled Normalizers in Logpoint Converged SIEM are responsible for parsing any log data into key-value pairs. When using the Compiled Normalizer to parse raw JSON logs, the number of fields increases with the complexity of the JSON data. Since there was no control over the complexity of the data in the log, blindly parsing JSON data as key-value pairs led to issues such as a large number of fields in the indexed log. This resulted in a larger index size, which impacted the storage and performance of the indexing layer, a critical service required for indexing fields before the start of analytics. It had a significant impact on the ability of Logpoint to manage and analyze logs effectively.
Now, with the JSONParser plugin users can extract values directly from JSON data in the search query, eliminating the need for exhaustive parsing of JSON logs through the Compiled Normalizer. The Compiled Normalizer can be modified to parse data, up to a certain level, with the remaining data stored as JSON strings. These can be parsed in the search query itself if the user needs the values inside them. By parsing the JSON log this way, the number of fields in the indexed log is drastically reduced, resulting in less storage space usage and cleaner parsing that does not affect the index layer.
For example, the following is the normalization of a CloudTrail log by its Compiled Normalizer before version 5.2.1.
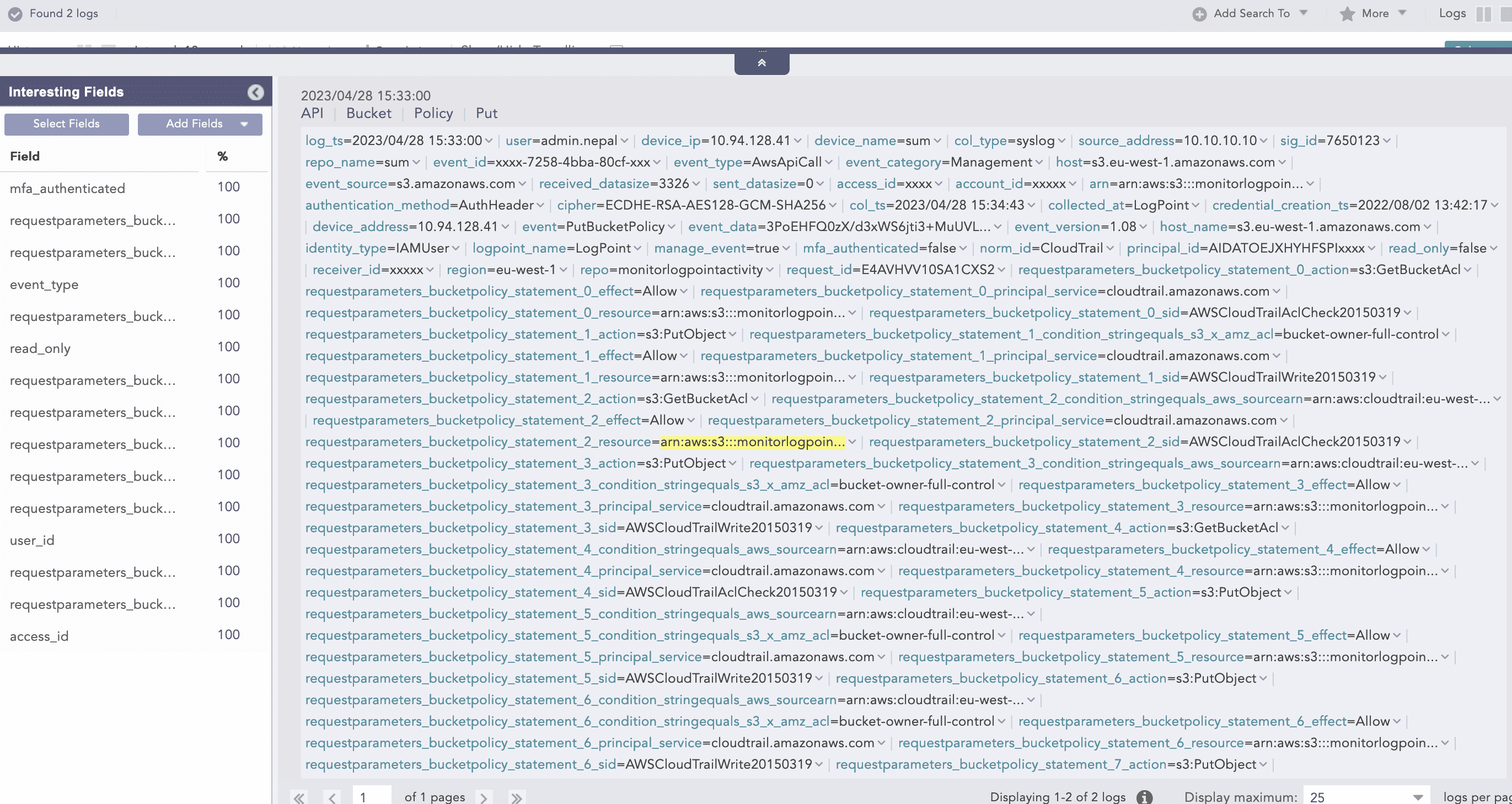
Uncontrolled indexing on the JSON Log of CloudTrail before v5.2.1
In version 5.2.1, we modified the normalization architecture of Cloudtrail's Compiled Normalizer to parse up to three levels of depth and convert any remaining JSON data into JSON strings, including JSON array objects. Therefore, the JSONParser plugin is a necessary tool for analyzing normalized data.
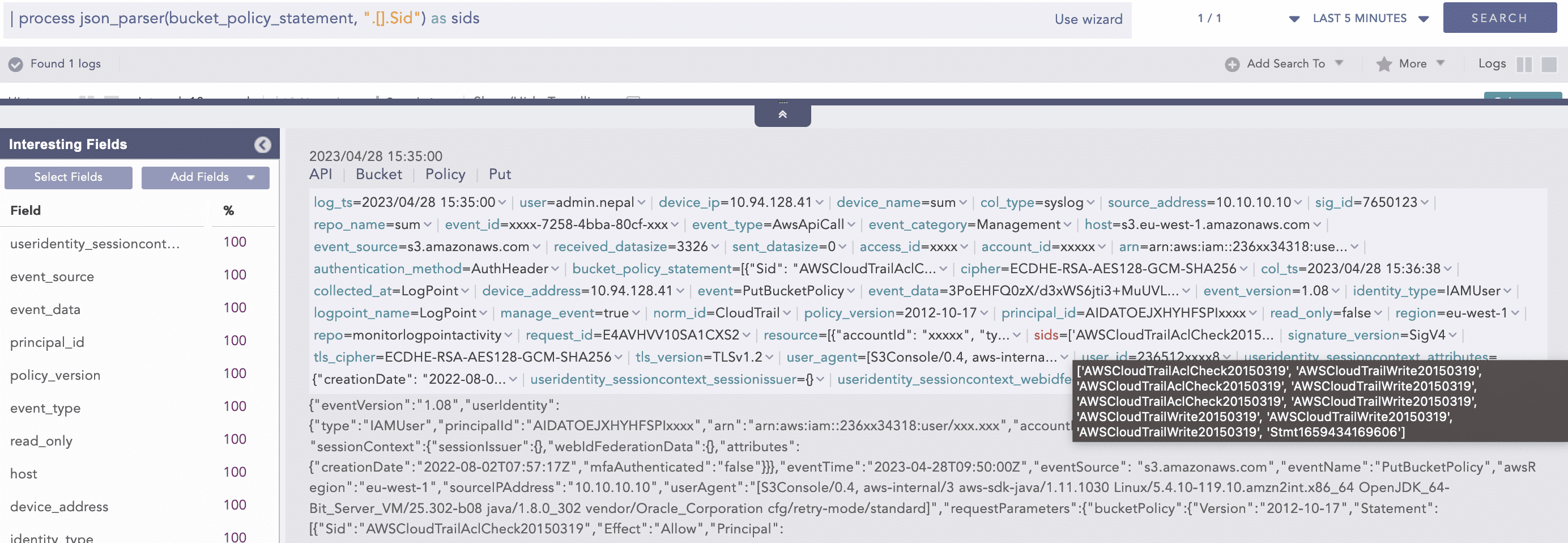
JSON array and object below three levels of depth stored as JSON string in CloudTrail Compiled Normalizer v5.2.1
As one can notice, we preserve all the values and only extract data if needed through process commands making indexing clean, readable, and efficient.
Conclusion
Apart from CloudTrail, other sources like Kubernetes, Azure, and more also generate JSON logs that contain multiple sub-events. With the release of the JSON Parser application plugin, Logpoint search queries now support JSON data types, which shall allow you to leverage and explore your JSON log events, with better performance.
In summary, the JSON Parser application plugin makes it easier to handle complex JSON log events and enhances the capabilities of Logpoint search queries by supporting JSON data types and improving the possibilities for aggregating on event sub-levels to better understand the data, gain insights, and identify patterns, leading to improved decision-making.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}