By Thomas Have, VP Product Development, 19 July 2016.
In a previous blog post, we described a new compiled normalizer for Windows. Continuing that, this blog post is the first in a series of blog posts on normalization in LogPoint in general. In this first instalment, we will explain what normalization means in a LogPoint context. The second instalment will look, in more detail, at the software architecture and the normalization possibilities LogPoint offer. Finally, the third instalment will look at additional features offered by this area of the LogPoint product.
Normalization is perhaps the key concept that allows us to transform like something this:
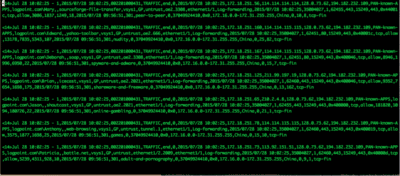
Figure 1: Sample logs
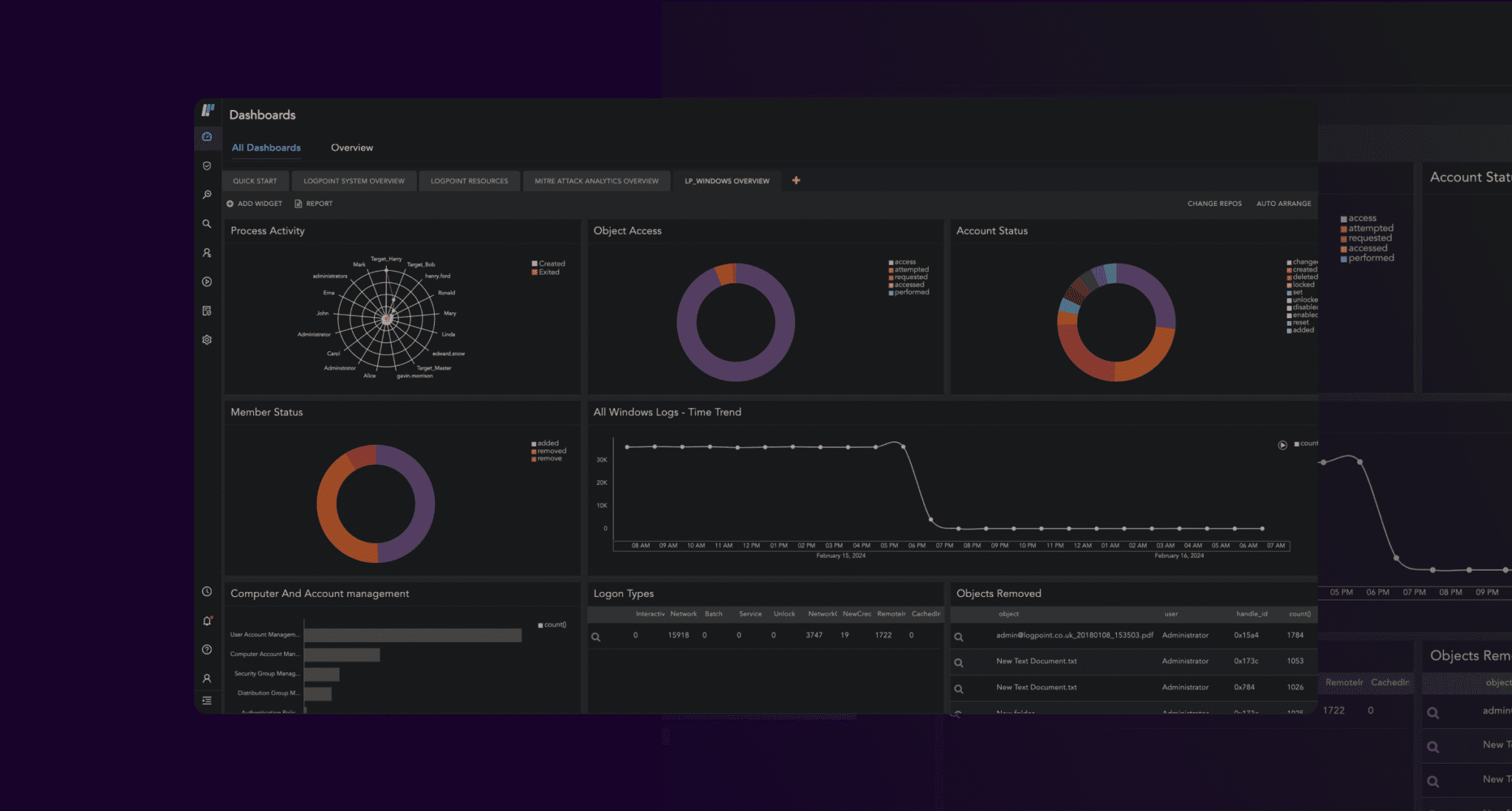
…into something like this:
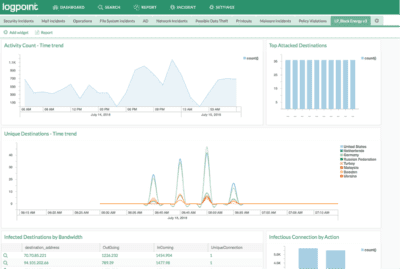
Figure 2: Sample dashboard
Transforming log events into graphs, very broadly, involves two things: Making sense of the log events and then graph that information.
Making sense of log events is called normalization. Normalization translates log events of any form into a LogPoint vocabulary or representation. The vocabulary is called a taxonomy. So, to put it very compactly normalization is the process of mapping log events into a taxonomy.
LogPoint can consume logs from many sources and all logs are normalized into a common taxonomy:
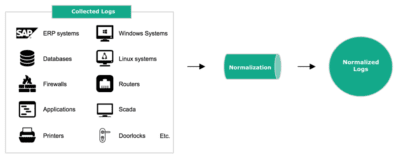
Figure 3: Normalization
In the next installment, we will look at normalization from a more technical perspective. But at this point we would like to mention a few things. LogPoint stores both the raw form of the log and the normalized version and searches can be performed on both. This is how it looks like in LogPoint:
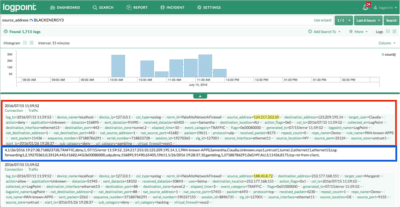
Figure 4: The red box contains the normalized part of the log. The blue box contains the received log.
At LogPoint, we have a team that manages the common taxonomy, provides normalization rules and uses of logs on top of the normalized logs – all of which is available for our customers as plugins.
The fact that LogPoint has a common taxonomy provides some neat benefits:
- Analysts, i.e. people working with data in LogPoint, can work in terms of the LogPoint taxonomy. So when setting up dashboards, doing ad hoc searches or the many other activities possible, the analyst doesn’t have to know the exact format of logs for each device: Just the LogPoint taxonomy!
- The common taxonomy allows customers to directly benefit from the R&D LogPoint is putting into understanding the various log formats and producing dashboards, alerts, reports and so on.
- People working with LogPoint are part of a community sharing the same language. So users can assist each other easily: Instead of asking a question like “I have PanOSYXZ logs and Zscaler logs, how do I graph this and that based on the origin and user over time?” you can ask a question like “I want to graph this and that based on source_addressand user over time” so other people can help out without knowing the exact format of the raw logs you’re working with.
- If an analyst chooses to work with LogPoint for a new employer, she can bring the knowledge of how to use logs with her: Not only will the administrative tasks on the LogPoint installations be the same, but all the knowledge about using logs will be preserved too. Which could potentially make on-boarding faster.
- LogPoint is in the SIEM domain – our world is server logs, security events, incidents and so on. How many ways do you really want to represent this kind of information? Why not standardize? After all, LogPoint doesn’t ingest logs about what color schemes are trending on the web.
We would like to mention that the LogPoint taxonomy is fully extendable and you can even replace it all together (the only restriction we impose is the representation of the time a log was generated and the time it was collected by LogPoint). However, doing so will require you to build all normalizations, dashboards and so on yourself.
We look forward to sharing more about normalization from a technical perspective in the next installment of this blog series.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}