By Thomas Have, VP Product Development, 22 August 2016
Welcome to the second instalment of our blog post series on normalization. In the first instalment, we described what normalization is in LogPoint and the benefits it provides. In this instalment, we will dig into the technical details of how normalization is done.
Collectors & Fetchers
To properly describe normalization from a technical perspective, we need to start by looking at how logs come into LogPoint.
The collectors and fetchers of LogPoint are responsible for interacting with the systems, from which LogPoint receives logs. Remote systems push logs into collectors and fetchers pull logs from the remote systems. Sometimes collectors and fetchers are collectively known as sensors

Collectors and fetchers are responsible for ‘chopping’ the event stream into individual logs. The ‘chopping’ process is called parsing in LogPoint. A very typical use case is reading a log file where each line is a single event – to do that you can, for example, set up an FTP collector and use a Line parser.
A collector or fetcher sends each log to normalization along with some additional information on when the log was received, what device was sending the log and so on. Let’s call that an adorned log.
The picture below gives a slightly simplified view of the steps:
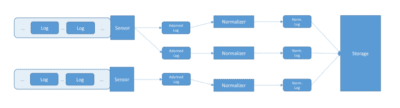
Design from a high-level
LogPoint normalizes logs in parallel: An installation can run many normalization workers simultaneously, on several servers in the same installation and on many cores on each server.
A normalization worker transforms an adorned log event into a collection, a normalized log:
- The original log in text format.
- A set of key-value-types tuples.
- A set of labels, which is a set of strings. Labels are beyond the scope of this blog post, but allow us to mention that they allow for easy searching for logs in common scenarios.
- The additional information of the adorned log about device, collection time and so on.
When an adorned log arrives at a normalization worker, first a decision on what normalization to use is made. The normalization can either be performed by a compiled normalizer or a RegEx normalizer, this is configured per log source.
RegEx Normalizer – versatile and always there for you
As the name suggests, the RegEx normalizer uses regular expressions to normalize logs. In fact, what really happens is that the user specifies the log format in a domain specific language. The specification is then transformed into a regular expression. The regular expression is used to extract the key-value pairs that are then annotated with the specified type.

RegEx normalization is built into LogPoint and is thus always available.
LogPoint provides a host of normalization packages for the RegEx normalizer for our customers to download.
Because of its versatility the RegEx normalizer can also be used to very quickly to support a new log source for a customer – either by the customer herself or LogPoint (depending on the contractual situation and so on).
The RegEx normalizer is versatile; however, its performance is in the range of 1000s EPS per CPU core.
Compiled Normalizer – fast and pluggable
In LogPoint version 5.4.1 we introduced the possibility of pluggable, compiled normalizers. A compiled normalizer consists of handcrafted code[1] that normalizes a specific log format into the LogPoint taxonomy. Because of this a compiled normalizer is generally very fast, with performance in the range of 20000s EPS[2] per CPU core.
So far we have released compiled normalizers for PaloAlto PanOS, CEF, Zscaler NSS and notably Windows Event Log (which you can read more about here). If your LogPoint ingests logs in one of those formats, do have a look at our download center, if you haven’t already, to get a speed upgrade!
Compiled normalizers are pluggable, so whenever LogPoint supports new formats through a compiled normalizer, that can be installed on existing installations.
Configuration of log sources – we tell you how
We require that the logs to be normalized by a compiled normalizer are in the specific format expected by the hand-crafted code. For example, the PanOS allows the administrator to configure the log format in many ways and we require that the PaloAlto firewall logging is configured in a very specific way.
This, including step-by-step guides of how to do it, is all included in the documentation provided by LogPoint for each compiled normalizer as applicable.
But wait – there’s more
Let’s take a closer look at the inner workings of a compiled normalizer. A compiled normalizer contains a pipeline through which the adorned logs travels and is transformed into a normalized log (the collection mentioned above).

In the Structuralizing step the adorned log is transformed into a map/dictionary/hash-map: For CSV-based formats the key is the field number and for key-value pairs the key in the map is the key-name from the format. Not surprisingly, this covers a plethora of log formats.
Using this approach any performance optimizations in text parsing CSV or key-value based formats, directly benefit all compiled normalizers that use one of these formats.
In the Taxonomification step the received map is converted into the key-value-type tuples – which is also represented by a map. For some formats the “taxonomification” is accomplished by looking up each key of the incoming map in a signature map and simply emitting the LogPoint key name and type. For other formats it’s more complicated.
Having a handcrafted taxonomizer also allows us to do normalization of values, however that is beyond the scope of this blog post.
In the Labelling step labels are added to the hash of key-value-types representing the almost normalized log, according to the handcrafted rules. Typically, these rules are pretty simple, often just consisting of the presence of keys or values in the normalized log and thus can be implemented really fast using lookups.
Why are compiled normalizers fast?
Beside all the usual benefits of handcrafted code, we would like to mention two reasons:
The developer knows the precise format and can thus target that format directly. For instance, if you know that timestamps are always of the format YYYY-MM-DD HH:MM:SS:MSS then it’s faster to normalize precisely that, rather than trying all supported formats.
And after the structuralization step most taxonomifcations (and labellings too) can be performed by look-ups, which are really fast, especially for CSV based formats (integer based lookups in arrays).
Concluding remarks
Thank you for reading this far on the more technical details and considerations of normalization in LogPoint. In the next instalment we will look at how we use the modular, pipeline approach of normalizers to create a whole new set of features.
————-
[1] Sometimes the hand-crafted code uses regular expressions too, but it’s not required to and can employ all sorts of very specific optimizations as needed.
[2] The actual mileage varies because some formats are computational expensive to normalize correctly – looking at you CEF ;)

![[🇫🇷 WEBINAIRE A LA DEMANDE] – Logpoint pour les centres hospitaliers](https://www.logpoint.com/wp-content/uploads/2025/05/logpoint-santexpo-2025-500x383.webp)

![[🇫🇷 WEBINAIRE] – Je découvre Logpoint après Forum InCyber 2025](https://www.logpoint.com/wp-content/uploads/2025/03/webinaire-forum-incyber-2025-500x383.jpg)


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}